如何用 AI 自动给 PDF 脱敏:免费、本地、不上传
一份 PDF 里散落着十几个人名、几个邮箱、几个手机号、还有家庭住址。法务要明天前全部涂黑。手动做意味着翻遍每页、找出每一处、画矩形覆盖,还要担心漏了一个。
用正则能抓住明显的模式——邮箱、规范格式的电话号码——但碰到人名就抓瞎了("苹果"是水果还是某 CEO 的姓?),国际电话格式也容易漏。最后还是得通读全文校对一遍。
这正是 AI 擅长的活。OnePDFs 的 Smart Redact 工具 把 OpenAI 开源的 privacy-filter 模型直接跑在你的浏览器里。它扫描每一页,识别 8 类隐私信息,让你审核后再应用。PDF 全程不离开你的设备——不上传、不登录、不收费。
这里说的"AI 脱敏"具体是指什么
网上多数所谓"AI 脱敏"的工具,要么把你的文件传到他们服务器(需要保护的恰恰是这种文件),要么背后就是个套了营销页的正则。Smart Redact 都不是。OpenAI 的 15 亿参数 NER(命名实体识别)模型在浏览器本地运行检测;浏览器没有可用缓存时会下载约 900 MB 模型,缓存仍在时可以复用。浏览器或用户可能清理缓存,届时需要重新下载。
一次扫描覆盖的 8 类隐私:
| 类别 | 例子 |
|---|---|
| 人名 | 像"张三"、"Tim Apple"——能区分人名语境和同形异义词 |
| 地址 | 街道地址、邮编、城市国家行 |
| 邮箱 | 标准格式 + 混淆形式(john [at] example.com) |
| 电话 | 国际格式、区号、分机号 |
| URL | http/https/ftp 链接和裸域名 |
| 日期 | 出生日期、文档日期,常见格式都识别 |
| 账号 | 信用卡片段、银行路由号、IBAN 形式串 |
| 密钥 | 不小心粘进文档的 API key、密码、token |
这就是正则做不到的部分。上下文很重要:模型知道"Apple Inc. 发布财报"里的 Apple 是公司,"我上周给 Tim Apple 发了邮件"里的 Apple 是人。
三步完成 PDF 脱敏
流程刻意做得简单——上传、扫描、应用。
第一步:打开 Smart Redact 工具
访问 /tools/pdf-smart-redact,把 PDF 拖到上传区。文件留在浏览器里,没有任何东西被发送出去。编辑器打开后,Smart Redact 子工具已经自动激活。
第二步:运行 AI 扫描
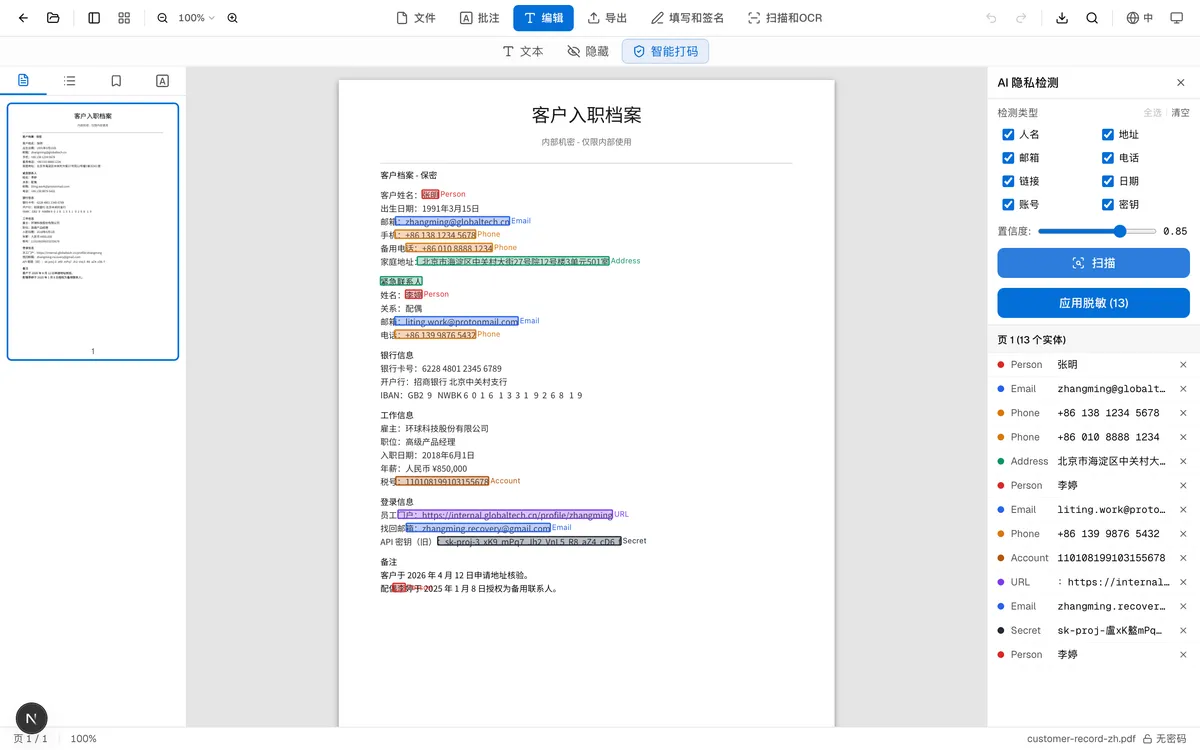
点 扫描。如果浏览器缓存里没有 privacy-filter 模型,需要先下载约 900 MB 数据;Cache Storage 里的副本仍可用时可以复用,但浏览器淘汰缓存或用户清理数据后会重新下载。加载和检测速度取决于网络、浏览器、设备、可用加速、页数和文档复杂度,没有固定完成时间。检测在本地运行,可用时采用 WebGPU,并使用浏览器兼容的回退方式。
扫描过程中,面板按页显示进度。识别到的项目按页分组列在面板里,每条同时在 PDF 上用对应类别的颜色高亮。
第三步:审核并应用
人工介入的环节。面板顶部有三个控件:
- 检测类型——8 个复选框,每个对应一类 PII。不想脱敏的类别取消勾选。比如日期是公开信息可以保留,取消"日期",PDF 上对应高亮立刻消失。
- 置信度阈值——0.50 到 0.99 的滑块。值越高误报越少但可能漏掉边界情况;值越低识别越多但会标出一些可疑项。默认 0.85 适合大多数文档。
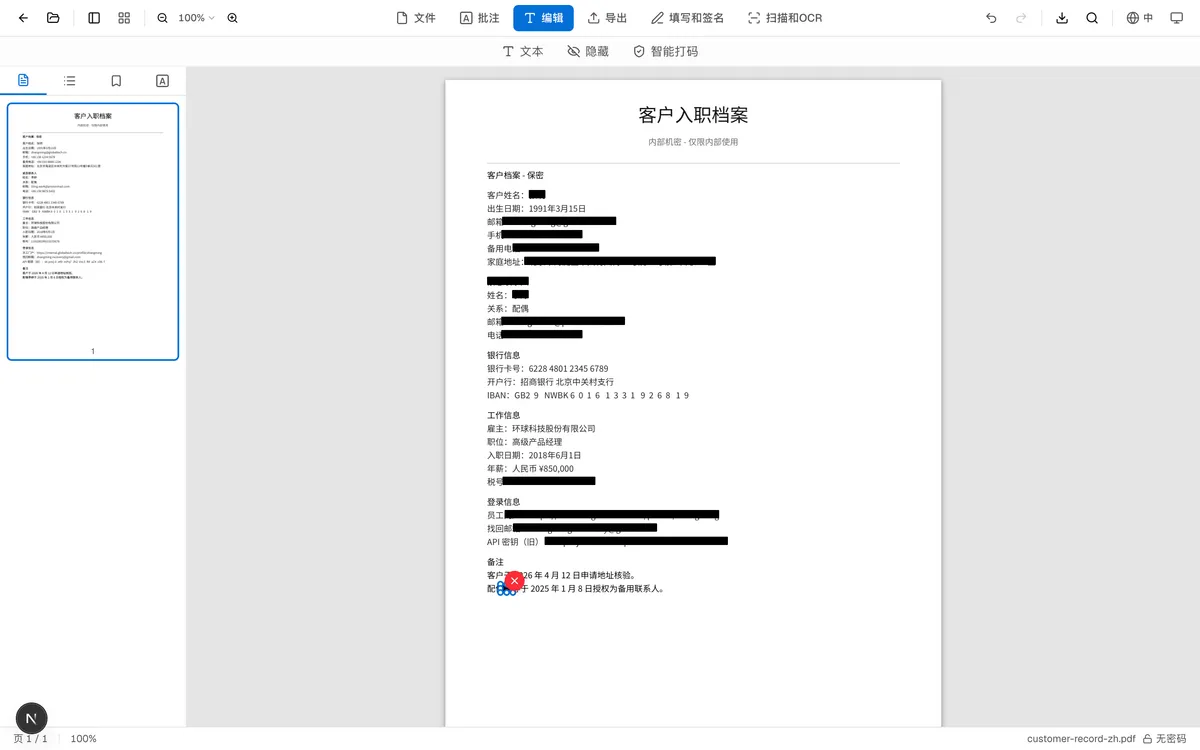
- 应用脱敏——最终动作。点击后,所有确认的项目都会加上一层不透明的黑色矩形。当前实现是在导出时把矩形画到对应位置,并不会删除底层文字对象或原始图像像素;它属于视觉遮盖,不等同于安全删除。
如果在列表里看到误判的项目,点旁边的 × 单独移除那一条。如果某个类别整体识别得不好,取消整个类别勾选。点击应用前只是预览候选项;点击应用也只是添加所选遮盖,不会擦除遮盖下的源内容。
为什么不直接用手动脱敏工具
OnePDFs 已经有 PDF 涂黑 和 PDF 擦除 用于手动脱敏,知道具体要藏什么、藏哪儿时它们很顺手。Smart Redact 在这些场景更优:
- 文档很长,想确保没漏掉
- 事先不知道里面会出现哪些人名或邮箱
- 想脱敏单一类别(比如只去所有电话号码)而不动其他
- 反复处理同类文档需要稳定的规则
对于普通审阅副本,可以先用 AI 扫描,再人工用手动工具复核。真正敏感的资料不能只依赖这种视觉遮盖:应使用能够移除底层内容的脱敏流程,并检查导出的文件。Smart Redact 是放大效率的杠杆,不是判断力或安全净化的替代品。
隐私保障
这种工具的核心矛盾是:保护数据本身的工具不应该成为数据泄漏的渠道。所以值得明确每一步都发生在哪里:
- 你的 PDF:留在浏览器。读进内存、由 pdf.js 提取文本,从不发送到网络
- 模型:缓存不可用时会从 HuggingFace CDN 下载约 900 MB 权重,并在可用期间存入浏览器 Cache Storage。缓存被淘汰或手动清理后可能再次下载。模型文件不会回传,推理在本地执行,不由 OnePDFs 服务器完成
- 检测结果:包含位置和置信度的实体列表,仅在浏览器内存里
- 视觉遮盖后的 PDF:本地用 pdf-lib 生成并提供下载。工具代码不会主动把检测到的文字或实体写入日志;但黑色矩形本身不能证明底层 PDF 内容已被删除
如果你在严格数据合规的企业环境里工作,这一点很关键。AI 看不到你的文档;它只是在已经加载页面的同一个 JS 运行时里跑。
AI 漏识别的情况
实事求是讲讲局限。privacy-filter 模型很好,但不完美:
- 没有文字层的扫描件:模型需要可提取的文本。纯图片 PDF(多数扫描件)无法工作——Smart Redact 按钮对这类文件会被禁用。应先用可信的 OCR 工具生成可搜索文字层,并核对识别文字是否准确
- 特殊语境下的人名:嵌在代码块里的人名,或非英文字符的人名可能被漏掉。降低置信度阈值能多识别一些,再人工复核
- 形似账号但不是账号的数字:发票号、SKU 编码等会被误判。要么取消"账号"勾选(如果文档里这类很多),要么逐条移除
普通审阅副本可以这样检查:默认设置扫描,带高亮通览一遍,确认后再点应用。导出后还要换一个 PDF 阅读器打开,逐项搜索被遮盖的值,并尝试选择、复制遮盖区域附近的文字。这些检查能发现遮盖失效或阅读器差异,但即使都通过,高敏感信息也不能只靠视觉覆盖来保护。
常见问题
收费吗?
工具不收订阅费,也不按页计费。浏览器没有可用缓存时可能需要下载约 900 MB 模型数据,产生的网络流量仍可能计入你的运营商套餐。
离线能用吗?
模型可用后,推理在本地运行;有缓存可以避免再次下载模型。但页面和所需应用资源是否仍在浏览器中也会影响离线使用,因此不能保证之后每个会话都能在断网状态运行。
支持非英语 PDF 吗?
privacy-filter 模型主要在英文数据上训练,但实测对中文文档也有相当的覆盖:常见的中文人名、城市级地址("北京市海淀区中关村大街...")、+86 手机号、邮箱、URL、Chinese ID/账号都能识别。中文日期、银行支行名等带中文上下文的数据偶尔会漏,遇到误判可以人工剔除。拉丁语系欧洲语言(西、德、法)的人名识别比中文更稳定。
应用脱敏后原始文字去哪了?
当前实现不会删除原始文字。“应用”会添加矩形遮盖,导出时把矩形画到页面上,或将其写成方形注释;底层文字仍可能留在 PDF 中。根据导出路径和阅读器不同,搜索、复制或文本提取仍可能暴露这些内容。因此它适合视觉遮盖和审阅,不应作为敏感数据的唯一保护;发送前应使用能净化底层内容的脱敏流程,并换阅读器验证导出结果。
能批量处理多个 PDF 吗?
界面上还不支持。模型按浏览器 tab 加载,但扫描流程一次跑一个文档。如果你有稳定的批处理需求,缓存模型 + 我们的 压缩 批量基础设施可以打通——欢迎反馈。
privacy-filter 模型是开源的吗?
是。在 HuggingFace 上以宽松协议发布。我们用的是 Transformers.js 移植版,让模型能在浏览器里推理。
试用
打开 Smart Redact,丢一个含个人信息的 PDF 进去,逐项审核 AI 找出的候选内容。缓存里没有模型时,浏览器可能需要下载约 900 MB 数据;缓存仍在时可以复用。总耗时取决于网络、浏览器、设备、页数和文档复杂度。
对于不适合 AI 的视觉遮盖场景——快速定点涂黑、矩形遮挡、手动白色覆盖——PDF 涂黑 和 PDF 擦除 更顺手。它们和 Smart Redact 互补,但都不能替代真正移除底层内容的脱敏流程。
整个流程都在你的浏览器里。不上传、不登录、不收费。这就是全部卖点。